


 Pandiri said he hopes for an in-person spring meeting. “It’s good for trainees to practice their presentations in front of a friendly audience,” he said. (Photo courtesy of Steve McCaw)
Pandiri said he hopes for an in-person spring meeting. “It’s good for trainees to practice their presentations in front of a friendly audience,” he said. (Photo courtesy of Steve McCaw)The Genetics and Environmental Mutagenesis Society of North Carolina (GEMS) chose the expansive topic of Big Data and Artificial Intelligence (AI) in Toxicology as the theme for its fall conference.
“We had excellent speakers, and attendance was on par with previous years, even though the meeting was online,” said outgoing GEMS President Arun Pandiri, Ph.D., head of the Molecular Pathology Group in the Division of the National Toxicology Program (DNTP).
How big is big data?
In her opening presentation, Alyson Wilson, Ph.D., from North Carolina State University (NCSU), said data generation worldwide this year will approach 44 zettabytes — 44 billion terabytes — and will increase to 163 zettabytes in 2025.
The rapid rise in data volume has led to an information bottleneck. “Our ability to collect data is outpacing our ability to turn it into useful information,” Wilson said. “Just because information is getting created doesn’t mean it is getting analyzed.”
Teamwork required
As the ability to collect and store large sets of raw, heterogeneous data increases, how it is organized becomes crucial.
“Clean, accessible data doesn’t happen by accident,” Wilson said. “Engineers need to store data in such a way that it can answer our questions when it’s retrieved.”
 Artificial intelligence is a term that is still evolving, according to Wilson. “It does not mean what it meant 10 years ago,” she said. (Photo courtesy of NCSU)
Artificial intelligence is a term that is still evolving, according to Wilson. “It does not mean what it meant 10 years ago,” she said. (Photo courtesy of NCSU)Knowing how to ask the right questions underscores the importance of subject matter experts who coax meaning from raw data. Meanwhile, managing such vast amounts of data calls for people with specialized skill sets in security, access, updating, analysis, visualization, and interpretation.
“Data science is a team sport,” Wilson explained. “Asking the right questions produces more information, which feeds right back into the data.”
Toxicology’s special challenges
Agnes Karmaus, Ph.D., a senior toxicologist at Integrated Laboratory Systems, LLC (ILS), an NIEHS contractor, offered a simplified definition of big data: It is data that is bigger or more complex than a spreadsheet can handle. She described challenges posed for toxicology by the onslaught.
“Our biggest hurdle used to be generating data big enough to conduct robust computational analyses,” she said. “We are no longer waiting for data. Tox21(https://ntp.niehs.nih.gov/whatwestudy/tox21/) and ToxCast high throughput assays can inform us about thousands of compounds. We are now at a stage where computational tools are needed to leverage big data most effectively.”
Changes to citation and publishing
 “The next challenge,” Karmaus said, “will be fast data — data that we can quickly extract from a mass and rapidly render actionable analysis outputs.” (Photo courtesy of Agnes Karmaus)
“The next challenge,” Karmaus said, “will be fast data — data that we can quickly extract from a mass and rapidly render actionable analysis outputs.” (Photo courtesy of Agnes Karmaus)As data sets are continually updated with new information, it is becoming more important to cite the version of the database used, or the date a website was accessed. This is especially true as more studies are data-based, rather than experiment-based, Karmaus noted.
“Make sure the data source and version are clearly retrievable. These things really help with transparency, which is critical to understanding the reproducibility of the study,” she said.
Toxicologists have a special responsibility to make sure decision-makers feel confident in their results. Karmaus pointed out that regulators need highly curated data so they can draw reliable conclusions about human safety.
New tools
Vijay Gombar, Ph.D., a cheminformatics scientist at Sciome, described Orbitox, an interactive 3D visualization and analysis platform for big data from varied scientific domains, with an emphasis on predictive toxicology. Sciome has a bioinformatics contract with NTP.
Michael Staup, Ph.D., a scientist with Charles River Laboratories, spoke on the use of machine learning and AI in pathological assessments.
(John Yewell is a contract writer for the NIEHS Office of Communications and Public Liaison.)
 “We have to learn to distill data down,” said incoming GEMS president George Woodall, Ph.D., from the U.S. Environmental Protection Agency. “But we have to be sure we haven’t distilled out something crucial.”
“We have to learn to distill data down,” said incoming GEMS president George Woodall, Ph.D., from the U.S. Environmental Protection Agency. “But we have to be sure we haven’t distilled out something crucial.”
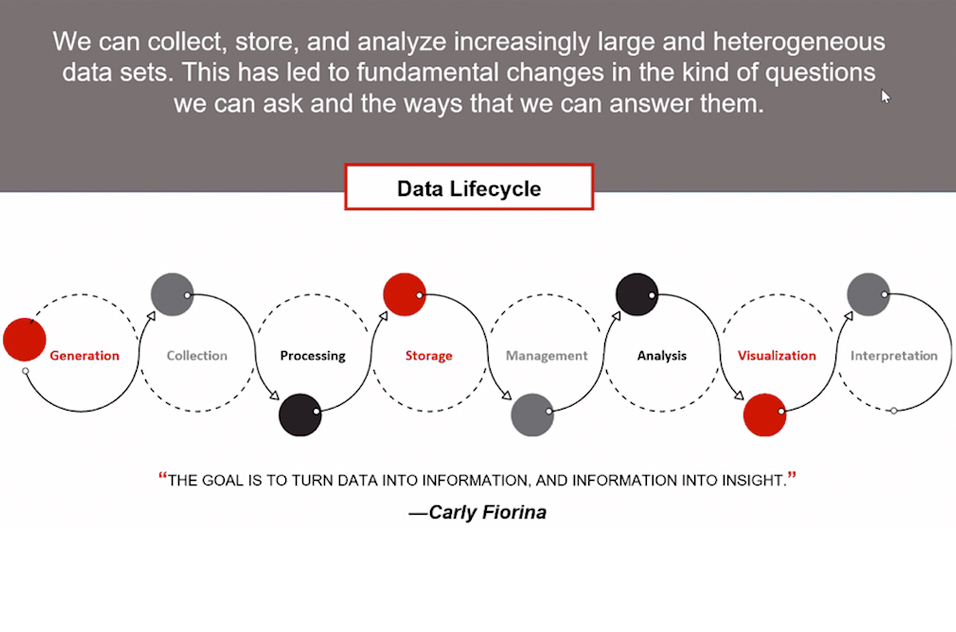 As we look at the data lifecycle, the activities on the left are associated with data engineering and on the right with data science. (Image courtesy of North Carolina State University)
As we look at the data lifecycle, the activities on the left are associated with data engineering and on the right with data science. (Image courtesy of North Carolina State University)
 “Predictive models and specialized cheminformatics tools make OrbiTox an excellent tool for in silico chemical profiling,” said Gombar.
“Predictive models and specialized cheminformatics tools make OrbiTox an excellent tool for in silico chemical profiling,” said Gombar.




